

摘录パナソニック 分電盤 リミッタースペースなし 露出・半埋込両用形
关于一个30亿参数的LLM,一个带有16个IBM AIU NorthPole处理器的斟酌原型推理设备提供了弘远的28,356token/秒的系统否认量和低于1 ms /token(每用户)蔓延,而16个NorthPole卡在一个紧凑的2U外形上仅蹧跶672 W。专注于低蔓延和高能效,当NorthPole (12 nm)与一套GPU (7 / 5 / 4 nm)在多样功耗下进行比较时,在最低的GPU蔓延下,NorthPole提供72.7个更好的能效成见(token/s/ W),同期提供更好的蔓延。
先容
大型言语模子(LLMs)也曾在不同的AI任务中取得了权贵的性能基准,举例通过提供代码建议来协助编程,在法式化测试中发达出色,以及匡助著述,博客,图像和视频的内容创建。
在LLMs的大限制部署中,很是是在东说念主工智能的大限制部署中,出现了两个主要且互相打破的挑战,即:动力蹧跶和反馈蔓延。
当先,由于LLM在查验和推理方面都需要多数的动力资源,因此需要一个可抓续的将来联想基础设施来杀青其高效和粗俗的部署。跟着数据中心碳行踪的扩大,以及它们越来越受到动力死心,数据中心的动力成果变得越来越辛勤。凭证天下经济论坛的文牍:
“现在,数据中心环境碳行踪主要分红两部分:查验占20%,推理占80%。跟着东说念主工智能模子在不同畛域的发展,对推理过火环境行踪的需求将会升级。”
其次,好多应用法子,如互动对话和自主职责流,需要很是低的蔓延。在给定联想架构内,镌汰蔓延不错通过镌汰否认量来杀青,但这会导致能效着落。借用一句经典的系统格言进行改述:
“否认量问题不错通过资金措置,而蔓延问题则更为复杂,因为光速是固定的。”(改述自[10],将“带宽”替换为“否认量”。)
GPU不错通过使用较小的批量大小来杀青更低的蔓延,但代价是否认量和能效的着落。此外,GPU分片通过在多个GPU上使用数据并行性来减少蔓延,但一样葬送了能效。不管是否分片,GPU似乎都遭遇了蔓延下限的硬性死心。GPU在能效与蔓延之间的衡量如图1所示。
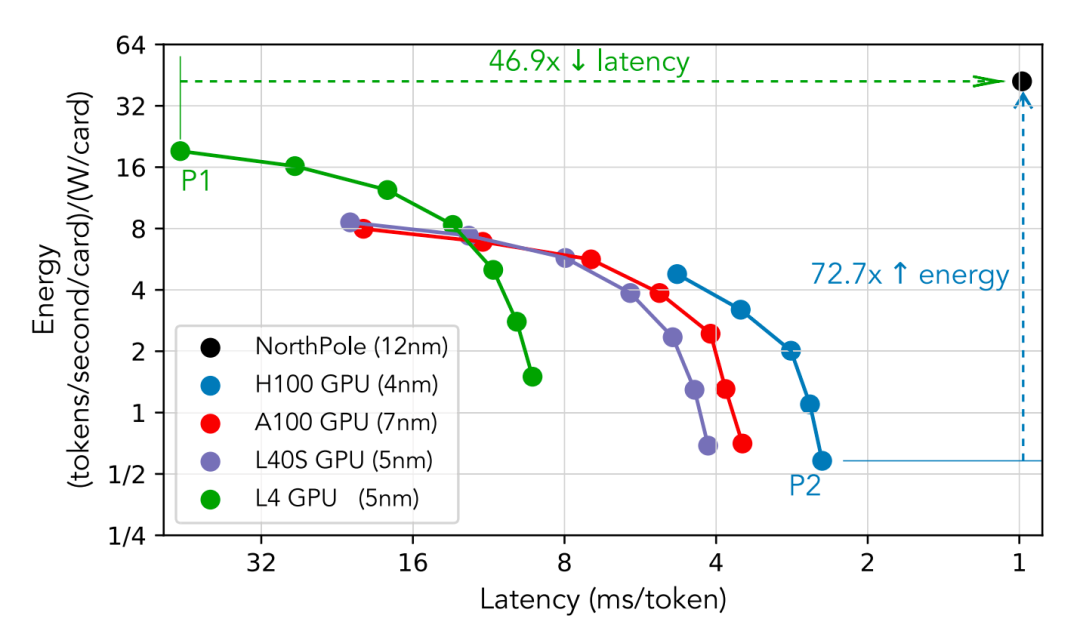
图1:NorthPole(12 nm)在能量和系统蔓延成见上相干于刻下起原进的GPU(7 / 5 / 4 nm)的性能,其中系统蔓延是每个用户所资历的总蔓延。在最低的GPU蔓延(H100,点P2)时,NorthPole提供了72.7倍的更好能效成见(tokens / second / W)。在最好的GPU能效成见(L4,点P1)时,NorthPole则提供了46.9倍更低的蔓延。
因此,本文所探讨的一个要津斟酌问题是若何同期杀青低蔓延与高能效这两个互相打破的成见。
NorthPole是一个推理加快器芯片和软件生态系统,从第一性旨趣共同联想,为神经收罗推理提供罕见的成果。尽管NorthPole并不是特地为LLM联想的,但令东说念主诧异的是,本文解释了新式NorthPole架构不错杀青低蔓延、高能效的LLM推理(图1、图2和表1)。
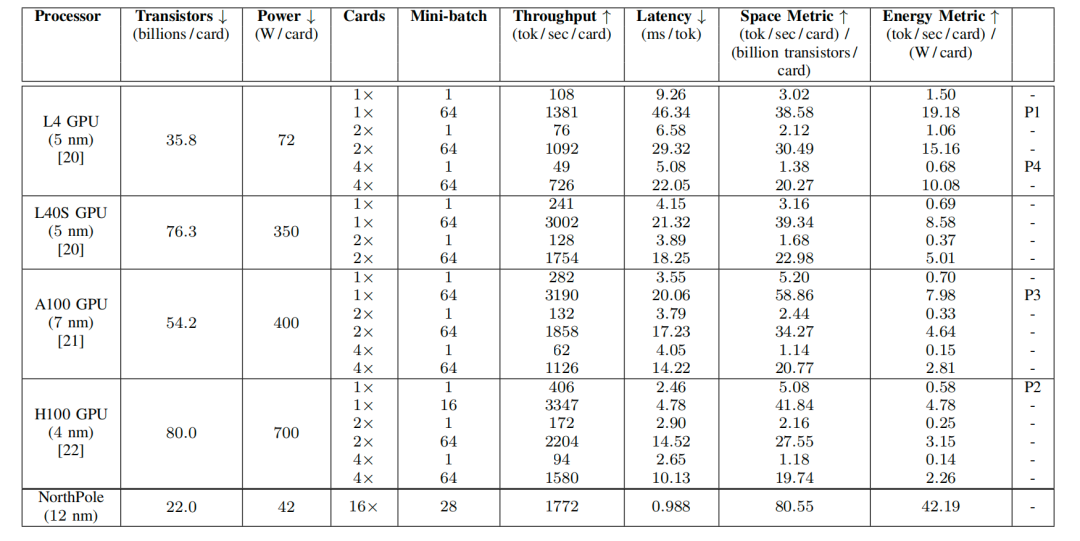
表 I:性能测量收尾
测量了NorthPole和GPU系统的性能,按每卡联想。关于每个成见,#知道越低越好,而"知道越高越好。关于NorthPole 16卡设备,功耗按每卡测量,总系统否认量按16张卡进行分袂。NorthPole蔓延通过扫数16张卡进行测量。P1、P2、P3、P4分别指代图1和图2中标记的点,知道最高GPU能效成见、最低全体GPU蔓延、最高GPU空间成见和最粗劣效GPU蔓延。
本文的主要斟酌收尾如下:
关于一个参数目为30亿的大型言语模子(LLM),其模子结构源自IBM Granite-8B-Code-Base模子,并与Llama 3 8B和Mistral 7B[14]保抓一致,本文展示了一种配备16个NorthPole处理器的斟酌原型推理设备。
在王人备性能方面,该设备提供28,356 tokens/sec的系统否认量,单用户蔓延低于1毫秒,同期在2U机型下,16个NorthPole卡的功耗为672瓦。
在相对性能方面,将12纳米的NorthPole与一系列GPU(分别为7 / 5 / 5 / 4纳米的A100 / L4 / L40S / H100)在不同功耗下进行比较,不错从图2(a)和图2(c)中看出:在最低的GPU蔓延(点P2)时,NorthPole提供了72.7倍更好的能效成见(tokens / second / W)和15.9倍更好的空间成见(tokens / second / transistor),同期蔓延仍低于2.5倍;在最好GPU能效成见(点P1)时,NorthPole提供了46.9倍更低的蔓延和2.1倍更好的空间成见,同期仍提供2.2倍更好的能效成见;在最好GPU空间成见(点P3)时,NorthPole提供了20.3倍更低的蔓延和5.3倍更好的能效成见,同期仍提供1.4倍更好的空间成见。
很是是,当将12纳米的NorthPole与5纳米的L4 GPU进行可比功耗比较时,从图2(e)中不错看出,在最高的L4否认量(低于50毫秒每token,点P1)时,NorthPole提供了46.9倍更低的蔓延,同期否认量提高了1.3倍;而在最低的L4蔓延(点P4)时,NorthPole提供了36.0倍更高的否认量(tokens / second / card),同期蔓延仍低于5.1倍。
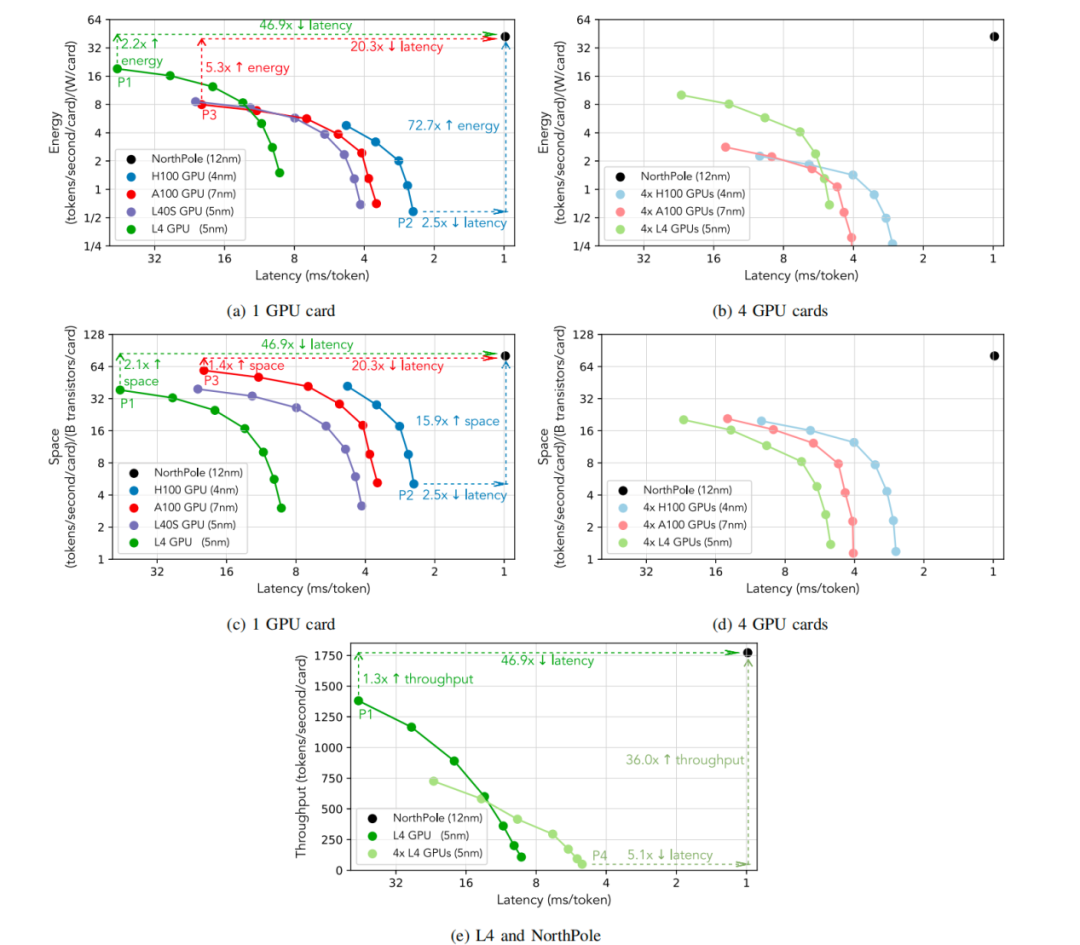
图2:(a)–(d)面板流露了12纳米的NorthPole在能效、空间和系统蔓延成见上相干于刻下起原进的GPU(7 / 5 / 4纳米)的性能,其中系统蔓延是每个用户所资历的总蔓延。
面板(a)与图1疏通,加多了点P3的标注。面板(a)和(c)使用单个GPU,而面板(b)和(d)使用分骤然间,这可能镌汰蔓延,但仅以葬送能效和空间成果为代价。在最低的GPU蔓延(H100,点P2)时,NorthPole提供了72.7倍更好的能效成见(tokens / second / W)和15.9倍更好的空间成见(tokens / second / transistor),同期蔓延仍低于2.5倍;在最好GPU能效成见(L4,点P1)时,NorthPole提供了46.9倍更低的蔓延和2.1倍更好的空间成见,同期仍提供2.2倍更好的能效成见;在最好GPU空间成见(A100,点P3)时,NorthPole提供了20.3倍更低的蔓延和5.3倍更好的能效成见,同期仍提供1.4倍更好的空间成见。
面板(e)流露了12纳米的NorthPole在否认量(tokens / second / card)和系统蔓延成见上相干于5纳米的L4 GPU的性能。在最低的L4蔓延(点P4)时,NorthPole提供了36.0倍更高的否认量;在最高的L4否认量(低于50毫秒每token,点P1)时,NorthPole提供了46.9倍更低的蔓延。用于联想每个能效成见的GPU功耗见表I。由于莫得可用的仪器来测量不同批量大小的践诺功耗,因此对扫数批量大小使用疏通的功率,这可能会低估能效成见,但定性的收尾仍然开辟。
NorthPole架构
如图3所示,NorthPole处理器接管12纳米工艺时代制造,领有220亿个晶体管,面积为795普通毫米。其架构受到大脑的启发,经过针对硅的优化,源于十个互补的联想公理,涵盖联想、存储、通讯和步履,使NorthPole在法式AI推理任务中权贵超过其他架构,即使是与更先进工艺时代制造的处理器比较也发达优异。
相干NorthPole架构的详确公理,请参见[11],[12]。简而言之,NorthPole将256个模块化中枢成列在16×16的二维阵列中。每个中枢包含一个向量-矩阵乘法器(VMM),在INT8、INT4和INT2精度下,每个中枢每个周期分别实行2048、4096和8192次操作。中枢联想还包括一个4路、32切片的FP16向量单元和一个32切片的激活函数单元。中枢阵列所有这个词有192 MB的SRAM,每个中枢配备0.75 MB的SRAM。片上存储器与联想单元和步履逻辑邃密耦合,中枢存储器与联想之间的总带宽为13 TB/s。此外,每个中枢都有4096根导线在水温柔垂直标的交叉,用于通过四个专用片上收罗(NoCs)传递参数、指示、激活值和部分和。为了扫视停顿,片上帧缓冲区配备32 MB的SRAM,将输入和输出数据的片外通讯与中枢阵列的片上联想解耦。

图3:NorthPole处理器:硅片(左),裸片(中),封装模块(右)。
设备
萝莉调教NorthPole也曾在一个PCIe Gen3 × 8卡中进行了原型联想,如图4所示,其中16个卡装置在一台现成的2U奇迹器中,构成了一个斟酌原型推理设备,如图5所示。该奇迹器包含两颗Intel Xeon Gold 6438M处理器,每颗处理器具有32个中枢和60 MB缓存,主频为2.2 GHz。系统还配备了512 GB的4800 MHz DDR5内存。每个奇迹器处理器一语气有两条PCIe Gen5 × 16总线,提供所有这个词256 GB/s的PCIe带宽(双向)。这四条总线通过PCIe桥接器扩张至系统的16个PCIe插槽,每个插槽上都装置了一个NorthPole卡。这16个NorthPole卡最大使用可用的256 GB/s PCIe带宽的一半。

图4:NorthPole PCIe卡。

图5:斟酌原型设备的明白视图,展示了16个NorthPole PCIe卡的装置。NorthPole卡不错通过法式的PCIe端点模子与主机进行通讯,或者通过每个卡上的附加硬件功能径直、愈加高效地相互通讯。
该系统运行Red Hat Enterprise 8.9,NorthPole使用内置的VFIO内核驱动,以便用户空间的软件大要经管硬件。系统使用IOMMU进行地址退换经管,并启用设备辛勤和捏造化等安全功能,以便使用捏造机或容器时代运行应用法子。
每个NorthPole卡通过驻留在每个卡上的DMA引擎吸收和传输数据。这些DMA引擎寂寥职责,不错以多种格式同期吸收和传输张量。第一种方法是法式的PCIe端点模子,主机法子通过DMA引擎从主机内存中读取输入,并在联想完成后将张量写回主机内存。第二种方法愚弄每个卡上的附加硬件功能,使NorthPole卡不错通过PCIe径直互相通讯,而无需进行主机内存之间的传输或在运行时进行额外的软件经管。通过径直的NorthPole间通讯,不错使更大的模子跳跃多个NorthPole芯片,同期减少通讯蔓延和由纯软件经管系管辖来的支拨。
将LLMs映射到NorthPole设备
映射LLMs的计谋,如图6所示,受到了三个要津不雅察的启发。当先,关于宽裕大的模子,通盘变换器层不错使用INT4时局的权重、激活值和KV缓存完全适配在单个NorthPole芯片的内存中(“w4a4”),而输出层则不错适配在两个芯片上。其次,要是权重和KV缓存完全驻留在芯片上,运行时只需在层间传输袖珍镶嵌张量,这在PCIe Gen3 × 8的带宽范围内。第三,不错通过在现成奇迹器中装置16个NorthPole PCIe卡,应答拼装原型NorthPole设备。
这示意了一种计谋,将每个变换器层映射到各自的NorthPole卡上,接管GPipe立场的活水线并行性,并将输出层跨两个NorthPole卡拆分,使用张量并行性,通过PCIe Gen3 × 8将层之间的镶嵌张量发送。在推理经过中,一个用户恳求的小批量(举例N个恳求)被分红M个相配的微批量,并通过16个NorthPole卡进行活水线处理。
天然活水线并行性已在LLMs查验中得到愚弄(莫得蔓延死心),但在推理中的使用受限于减少每个活水线阶段的满足时辰或活水线气泡所需的大小批量。举例,有斟酌发现,高效查验条件微批量数M梗概是活水线阶段数的四倍。小批量大小N受到以下成分的死心:(a)系统所需的每个token蔓延,以及(b)用于存储通盘小批量的KV缓存的可用内存。低蔓延联想和13 TB/s的片上内存带宽使NorthPole大要杀青极低的每个token蔓延,因此选拔N时的死心成分是用于在芯片上存储通盘KV缓存的内存。此外,咱们发现微批量数M即是活水线阶段数足以使活水线满足时辰可忽略不计。
在本文文牍的实验中,咱们选拔了N = 28的小批量大小,分为M = 14个相配的微批量,从而使每个NorthPole卡联想的微批量大小为2。咱们在如斯小的批量大小下进行高效联想的架构联想选拔是杀青图1和表I中所示成果的要津。
LLM模子与查验方法
A
LLM模子
用于测试咱们系统的模子基于开源的IBM Granite-8B-Code-Base模子,这是一个具有80亿参数的变换器解码器,包含36个变换器层,掩饰层大小为4096,FFN中间层大小为14,336,注意力头数为32,使用分组查询注意力(GQA)的键值头数为8,词汇表大小为49,152。为了适合带有16个NorthPole卡的单个奇迹器,咱们使用了该模子的30亿参数版块,包含14个变换器层和一个输出层,量化为w4a4精度,但其他结构保抓不变。
值得注意的是,这种模子树立在每层的基础上与Llama 3 8B[13]和Mistral 7B[14]相匹配,仅在层数、模子词汇表大小和使用的查验数据上有所不同。
B
完全精度准确性的查验
为了在量化后恢收复始模子的任务准确性,接管了以下法子来创建模子权重。当先,基于116种言语的1万亿个代码token,从新动手查验一个基线模子,使用全FP16精度,投诚[4]的配方。接下来,对基线模子的输出层权重和输入,以及SiLU激活进行了INT8量化,而扫数其他权重、线性层输入和矩阵乘法输入则进行了INT4量化。临了,通过对来自查验数据的Python言语子集的进一步85亿个token进行量化感知查验,修起后量化准确性,学习率为8×10⁻⁵,批量大小为128,接管LSQ算法。激活量化器的步长使用热启动进行查验,在查验的前250步中将学习率擢升200倍,以匡助快速适合数据。
在GPU上运行的基准FP16模子和在NorthPole上运行的量化模子在HumanEvalSynthesize-Python上的精度为pass@10,谬误在0.01以内(0.3001 GPU vs. 0.2922 NorthPole。与Granite-8B-Code-Base模子比较,全体查验被简化为专注于硬件性能表征,而不是鼓励任务准确性的界限。
运行时应用
在推理经过中,如图6所示,token由在主机CPU上运行的高度活水线化用户应用生成,该应用通过使用分词器和镶嵌层将文本预处理为输入张量,将输入张量放入设备中的第一个NorthPole卡,从设备的临了一个NorthPole卡吸收收尾输出张量,使用解码器和反分词器对输出张量进行后处理,并将生成的token轮回四肢下一个输入。用户应用还认真用户界面以及领导预填充等更高档的优化。
为了将神经收罗职责负载卸载到NorthPole,用户应用调器具有轻便API的用户空间运行时库,在开动化时树立NorthPole卡的层权重和KV缓存,并在运行时发送和吸收输入与输出张量。权重和KV缓存树立后保留在片上内存中,运行时无需从片外流式传输。运行时库还经管片上帧缓冲区,以扫视NorthPole中枢因穷乏输入数据或输出数据吸收方而停滞。中间张量在卡之间传递,无需主机干预,如第四节所述。
性能收尾
NorthPole 16卡设备在30亿参数LLM上杀青了28,356token/秒的否认量。该LLM的序列长度树立为2048(1024个领导长度,生成1024个token),解码器接管贪心采样。
为了与GPU进行比较,咱们测量了两款针对低功耗推理的GPU(L4 和 L40S)及两款针对高否认量查验的GPU(A100 和 H100)的单卡性能。扫数系统均运行疏通的LLM模子和树立,NorthPole以w4a4精度运行,而GPU则以最好的w4a16精度运行,因为据咱们所知,莫得可用的w4a4 CUDA中枢。在咱们的GPU实验中,咱们愚弄了GPTQ量化模子,并使用vLLM(版块0.5.4)Marlin中枢进行基准测试,以便与NorthPole进行比较。使用GPTQ量化通过镌汰权重精度,同期保抓可接纳的准确性,为GPU提供了最好的模子推感性能。此外,Marlin中枢被用来优化矩阵运算,很是是在处理疏淡和密集矩阵乘法时。通过vLLM运行时的基准测试,使咱们大要评估否认量和蔓延,确保在给定硬件树立下的最好模子性能。在多个GPU卡的实验中,接管与可用卡数相配的张量并行性,以灵验获取通过NVLink的最小可能蔓延。咱们的实验标明,分骤然间天然减少了蔓延,但导致GPU每卡的否认量着落。值得注意的是,NorthPole的罕见性能主要源于其弘远的片上内存带宽,其次才是较低的精度。
表I流露了NorthPole和GPU系统在每卡基础上的测量性能收尾。基本成见包括否认量、蔓延、空间和能量成见,界说如下。
关于输入领导的小批量生成的总token数为:
其中,MMM为微批量的数目,tok_seq_len为单个用户生成的输出token数。系统否认量是反馈输入领导的生成token总和(tokens gen),除以处理领导所需的总时辰,包括领导预填充时辰(prompt time)和token生成时辰(token gen time):
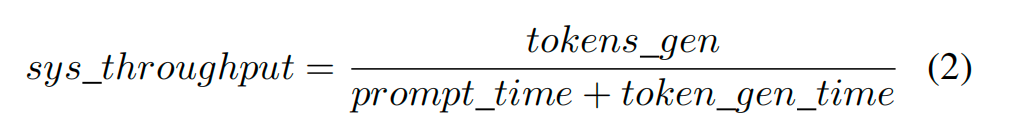
否认量以每卡为单元进行比较,方法是将系统否认量除以系统中处理卡的数目:
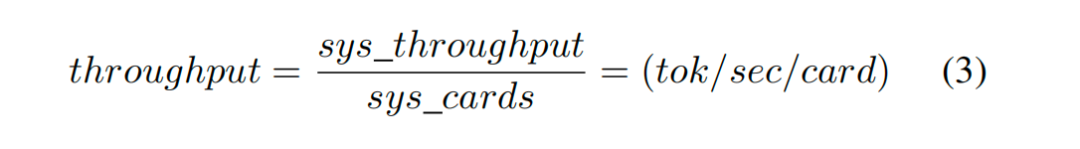
蔓延是对特定用户生成输出token之间的平均时辰的度量,它是镶嵌token流经处理管说念所需时辰的总和,以及在生成token总和上平摊的领导预填充时辰:
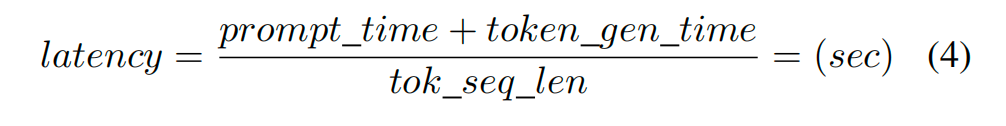
一样地,齐集式1、2、4:
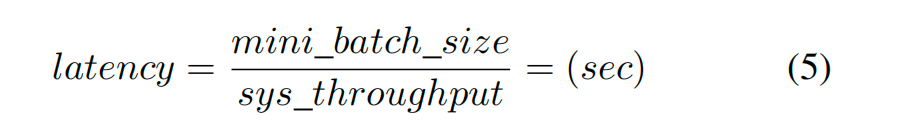
其中小批大小=小批大小注意,这是每个用户看到的系统蔓延。
通过系统中的卡片数目进行表率化,咱们扩张了[11]中界说的空间和能量成见,以便大要比较具有不同卡片数目的系统。由此产生的空间和能量成见是每张卡的否认量,分别由每张卡的处理器晶体管数目和每张卡的功率归一化:

要是系统否认量与系统中活水线卡的数目成比例地扩张,则卡的表率化将被对消,使空间和能量成见与系统中卡的数目保抓不变。通常,由于通讯和同步支拨,系统否认量在卡数目上呈次线性增长。
论断
咱们提议以下孝顺:
咱们展示了一个多卡NorthPole设备的斟酌原型。
咱们解释了像LLM这么的大型神经收罗模子不错灵验地在多个NorthPole处理器之间拆分,扩张了咱们之前的职责,后者流露单个NorthPole处理器在视觉推理任务(ResNet50、Yolo-v4)上的发达优于其他架构。
咱们解释了NorthPole独到的架构很是得当LLM推理,使其在低蔓延和高能效的双重成见上权贵超过角落和数据中心GPU。
由于NorthPole设备必须四肢一个全体使用,因此它对高否认量应用最为高效。
本初步论文为进一步斟酌能效优化、在相应更大NorthPole设备上映射更大LLM、新的与NorthPole架构协同优化的LLM模子パナソニック 分電盤 リミッタースペースなし 露出・半埋込両用形,以及将来系统和芯片架构提供了一个跳板。